At first I thought we needed to move the thread’s computational work to the GPU, but it seems that this is not the intention of the documentation, because to do so we would have to change the source file extension to .cu and modify the compilation method, which does not meet the submission requirements. ![]()
I saw the following sentence in the teaching assistant’s publicly shared article:
Starting 8 threads can achieve a speedup ratio of over 4
(edit1 source: https://xjtu.app/t/topic/9693
The document’s screenshot also indeed shows that 8 threads achieved a speedup of \frac{7.569}{1.231}=6.15, but if the eight threads are shared among the three types VertexProcessor::worker_thread, Rasterizer::worker_thread, and FragmentProcessor::worker_thread, assuming the workload is mainly determined by fragment processing and each type must have at least one thread, then the best case would be:
VertexProcessor::worker_thread: 1
Rasterizer::worker_thread: 1
FragmentProcessor::worker_thread: 6
The speedup probably wouldn’t exceed 6.
Because the ideal scenario is that the 6 FragmentProcessor::worker_threads can completely fill the idle time, reducing that portion of time t_0 to \frac{1}{6}t_0
( I’m not sure if this analysis method is correct, or perhaps we can treat these three functions as thread foremen, using std::thread inside these foreman threads to spawn worker threads to do the work? ![]()
Similar to the figure below:
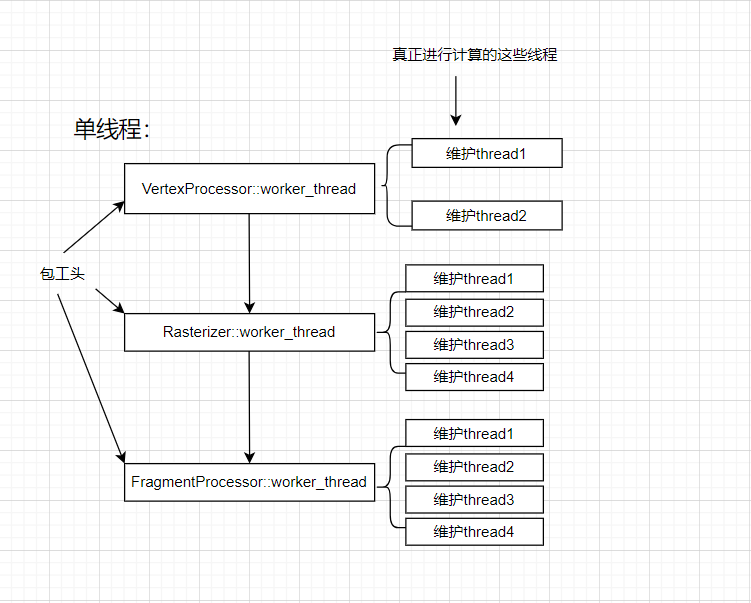
![2d6fdd877df889eff693e10233ca79b5|690x324, 75%](upload://aU9aP5l