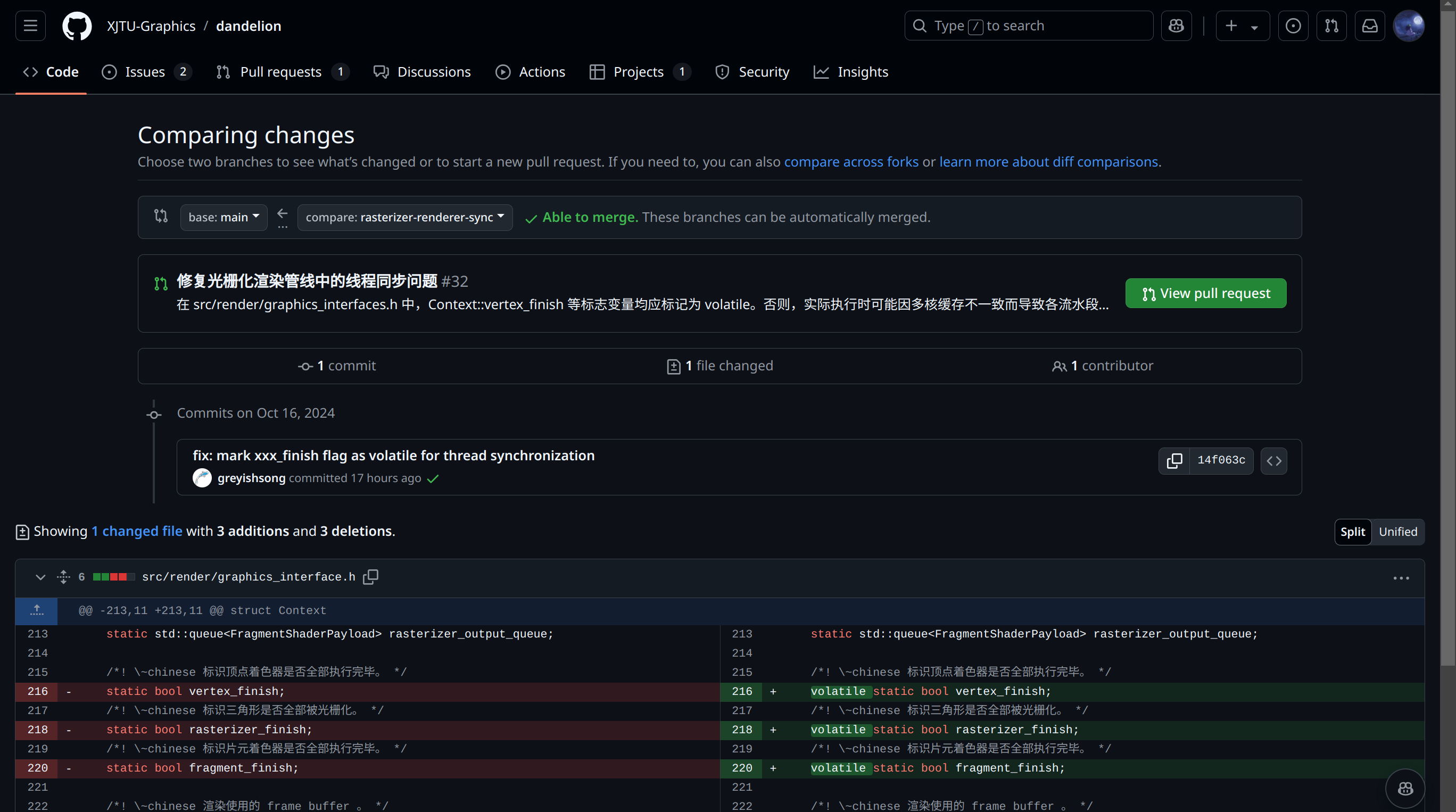
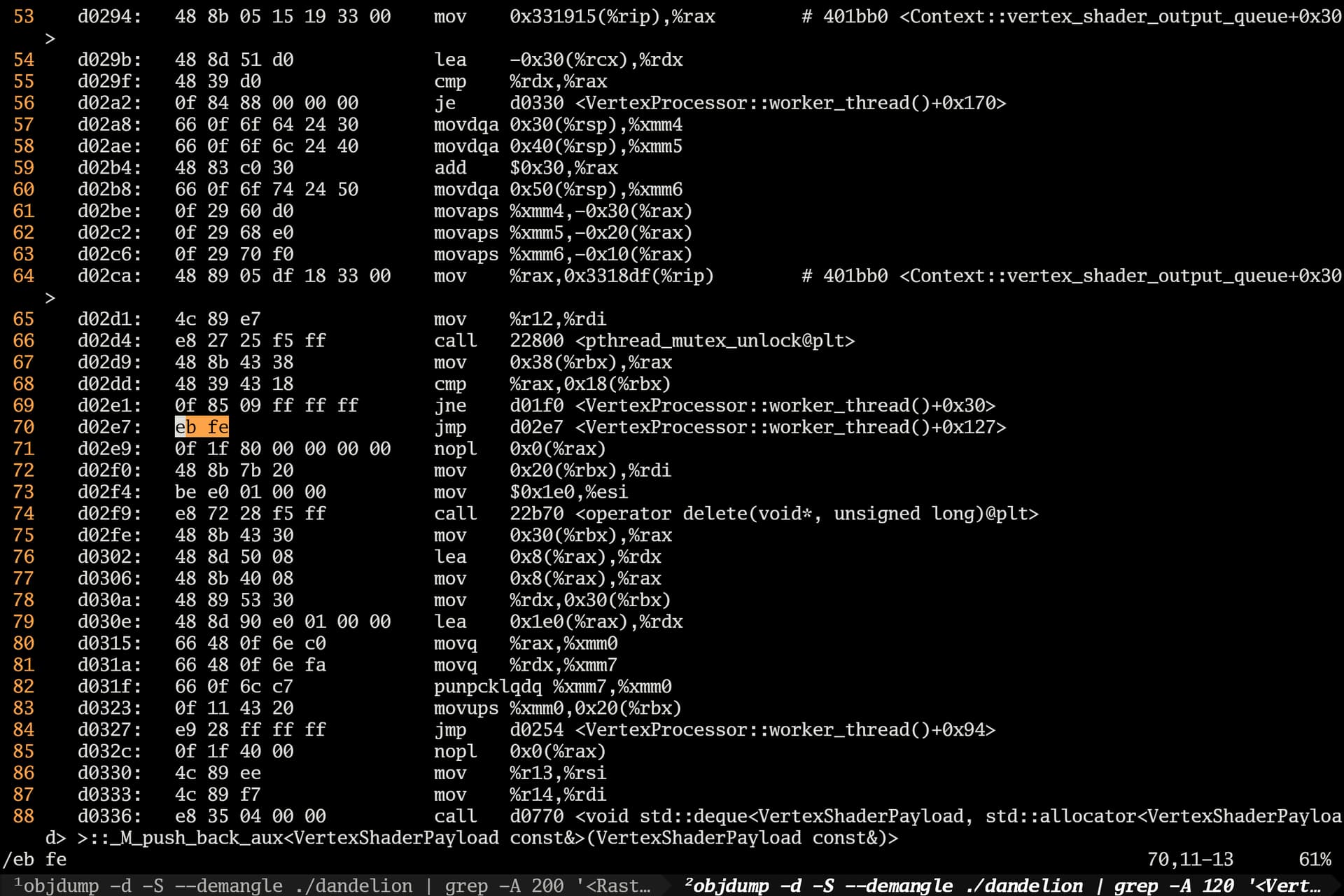
Problem Description
In a program compiled with gcc 14.2.0, the issue occurs only in Release mode. The problem is reproduced on two Windows computers with similar environments.
Rendering Behavior
-
First click render
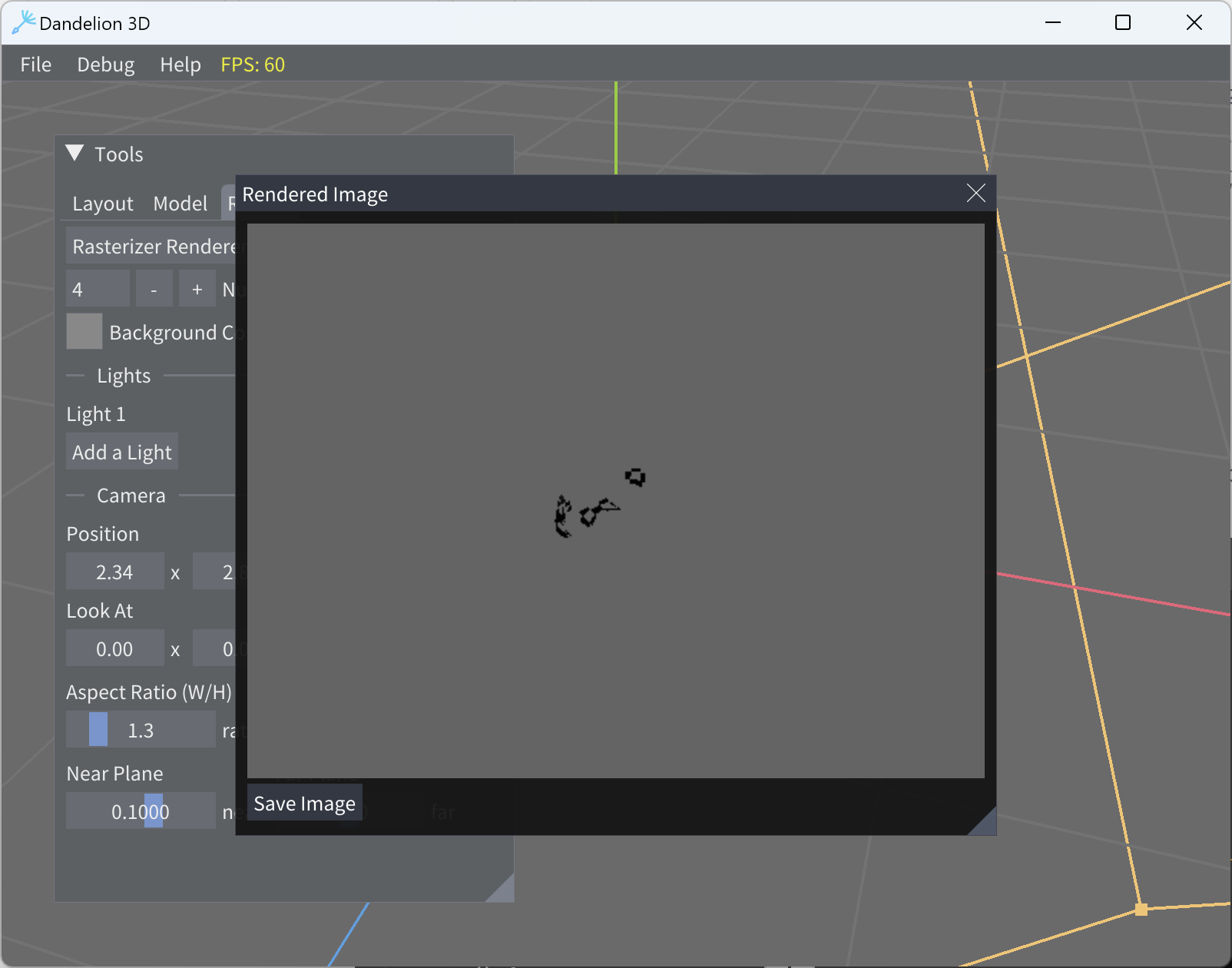
-
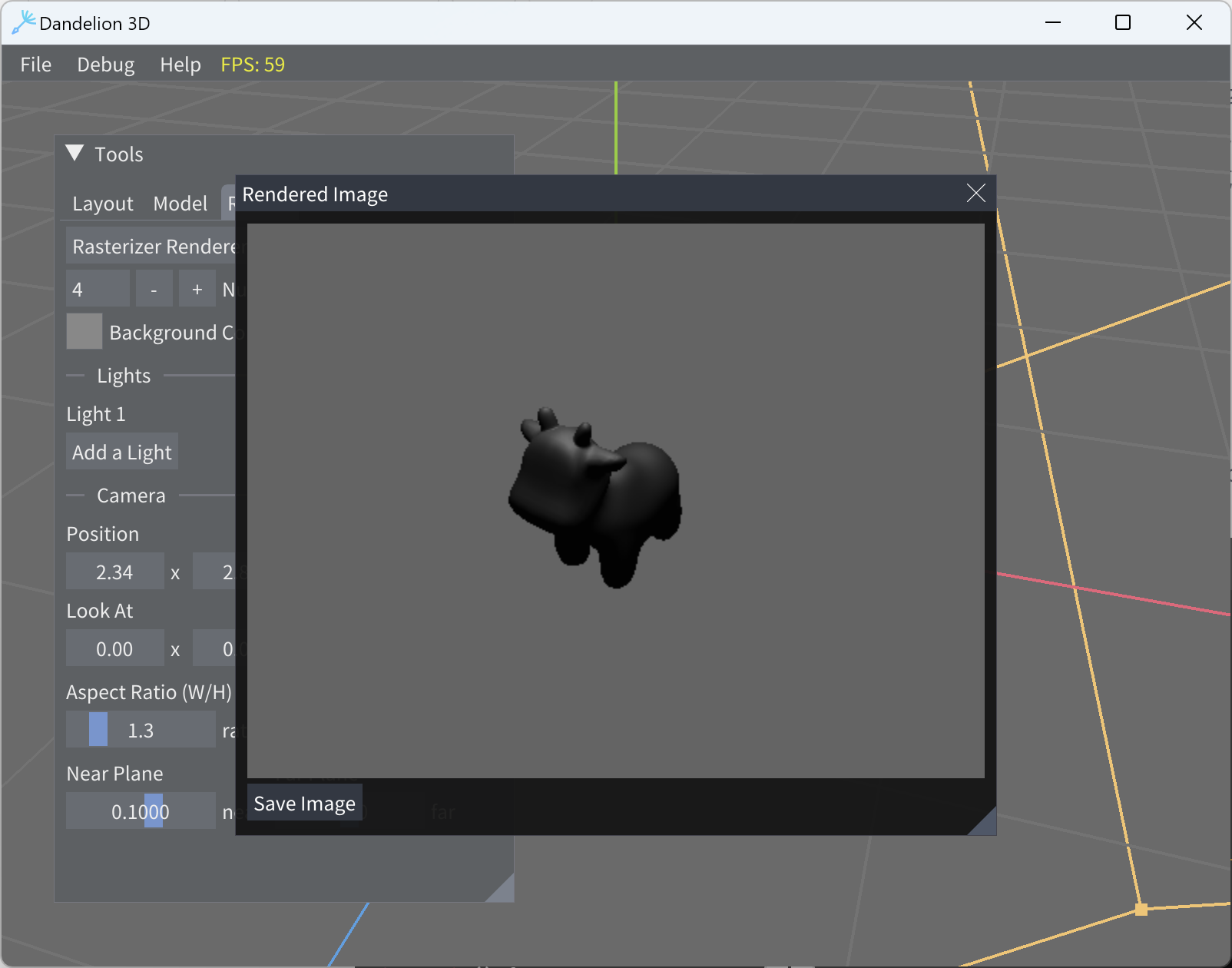
Second click render
-
Third click render
After modifying the camera light parameters, the third click render looks like two images are stitched together.
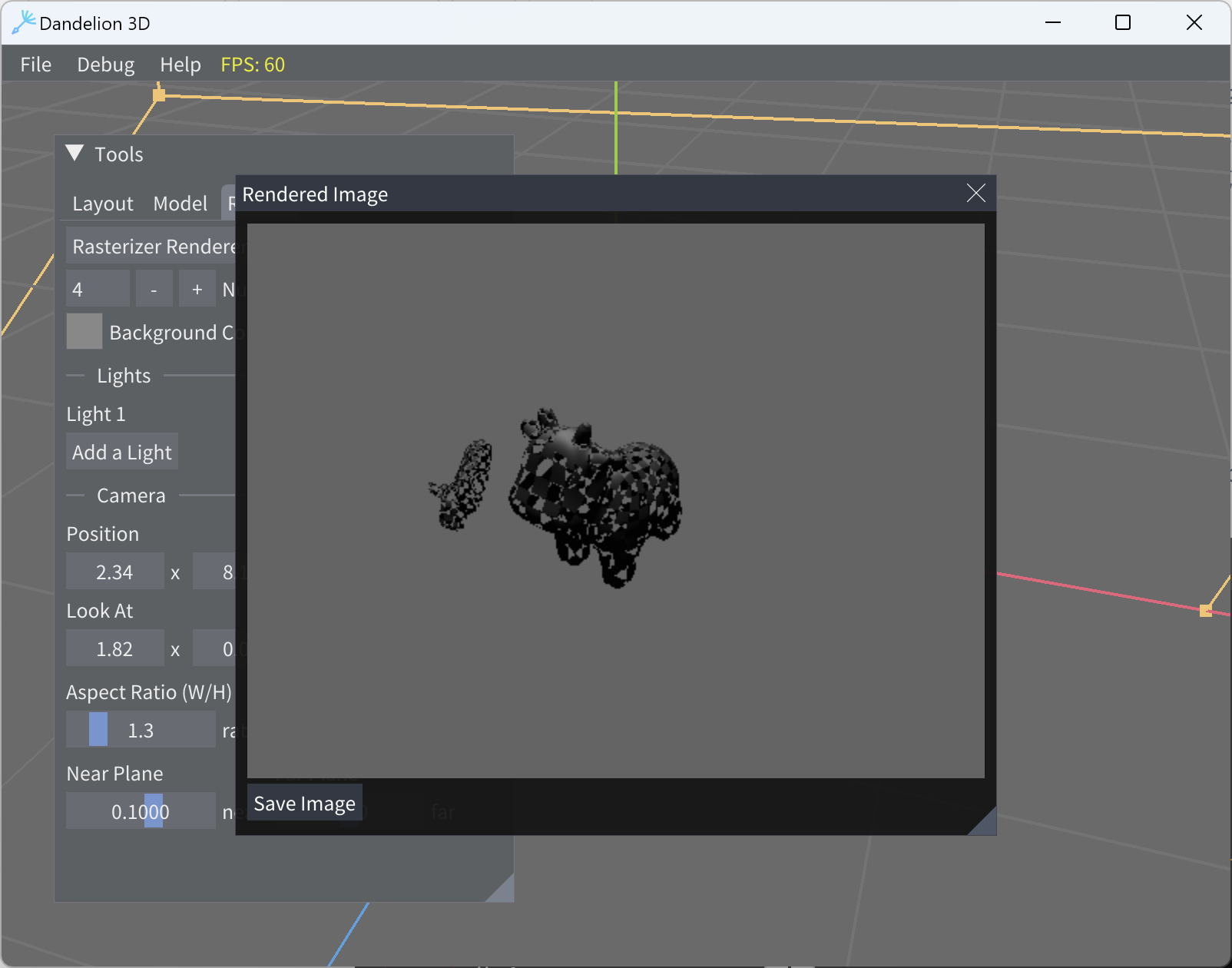
-
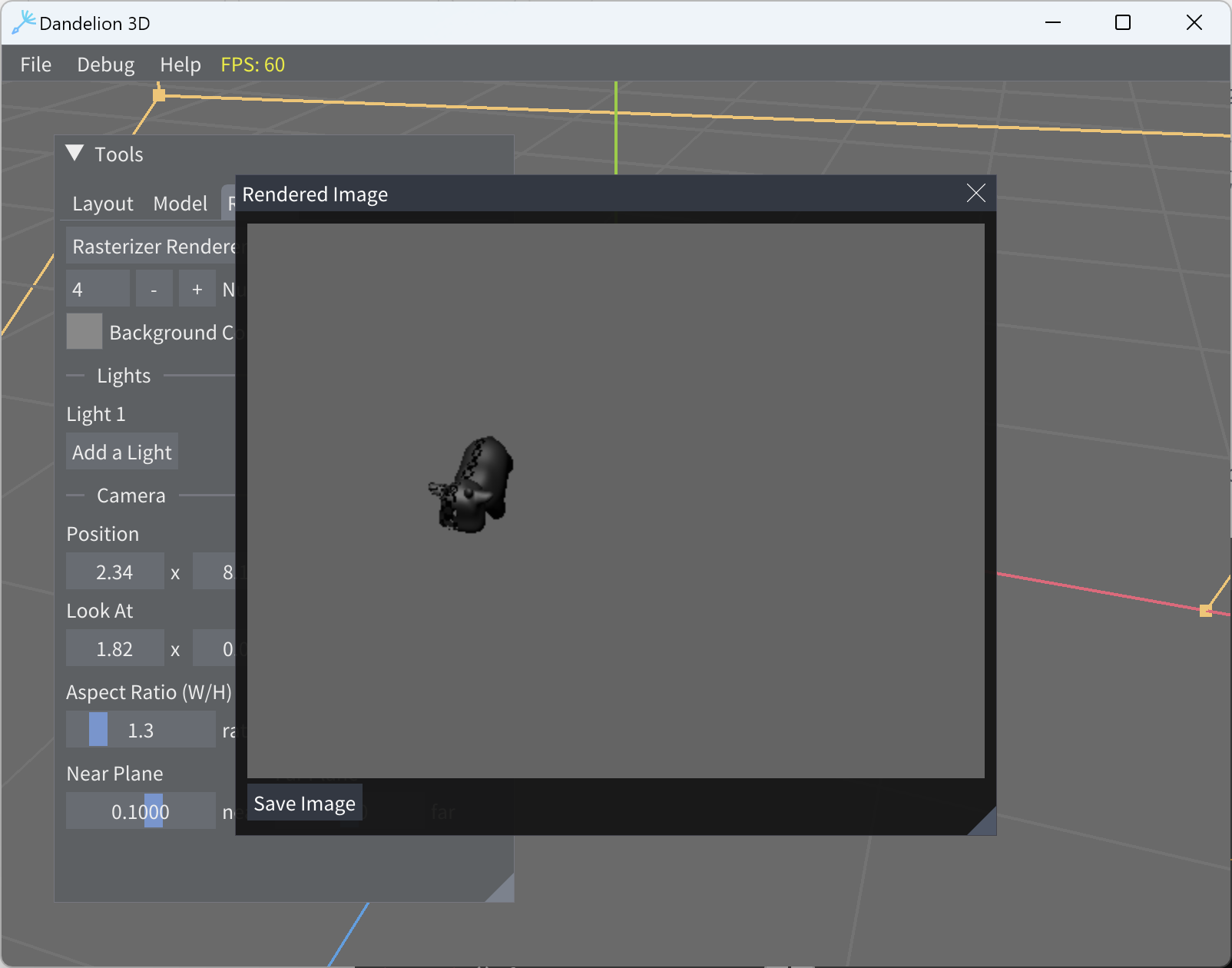
Fourth click render
Log Output
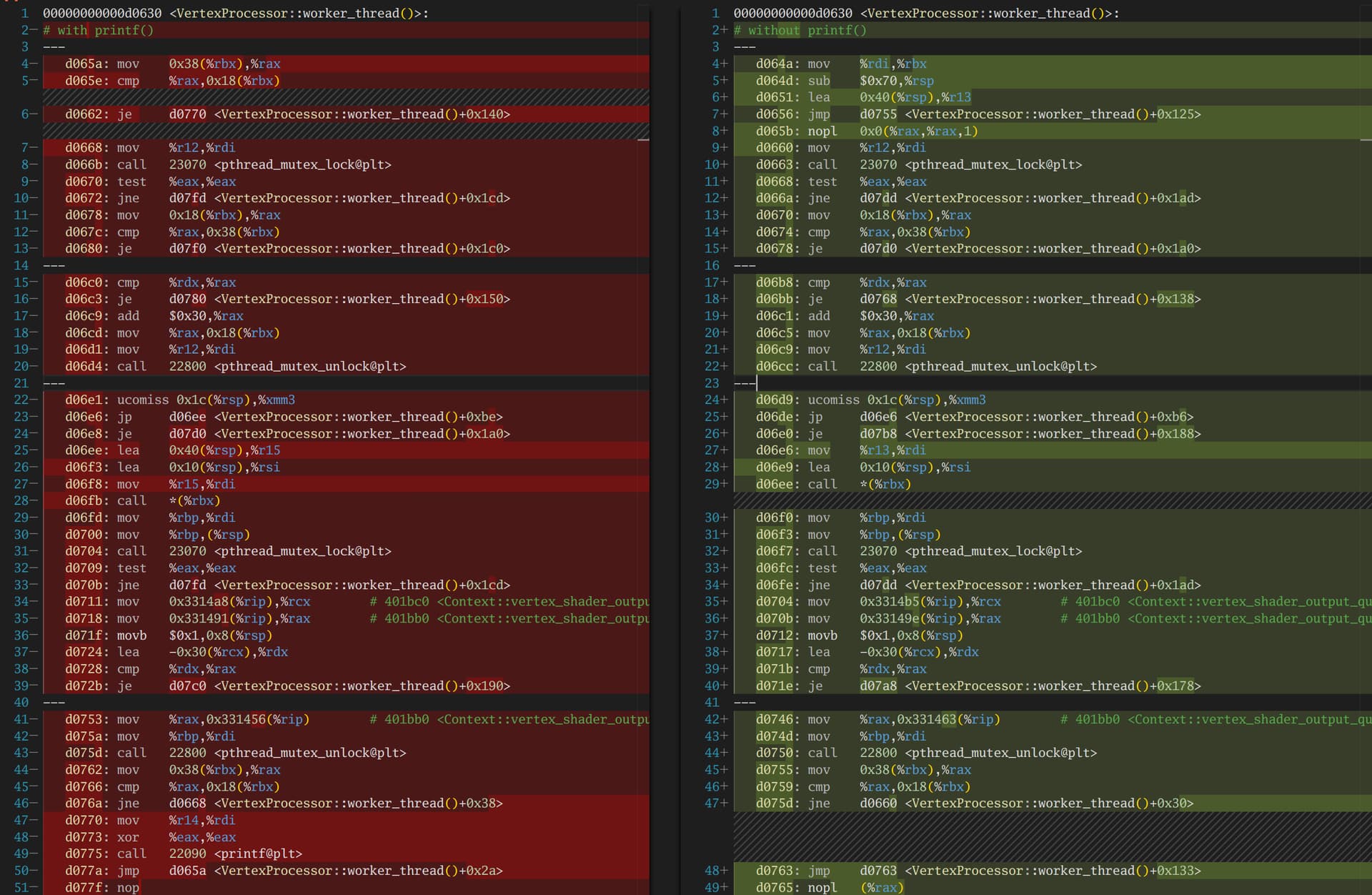
Initially thought it was a loading issue. Using printf (because spdlog crashes the program when printed at the same location, and dandelion seems to use a single‑threaded spdlog, while printf appears thread‑safe) to print logs revealed that fragment finished before rasterized.
vertex_processed:17568 rasterized: 5856 frag_num:306 dropped:23 [Rasterizer Renderer] [info] rendering (single thread) takes 0.005859 seconds
[Rasterizer Renderer] [info] finished render data load
vertex_processed:17568 rasterized: 5856 frag_num:17382 dropped:8847 [Rasterizer Renderer] [info] rendering (single thread) takes 0.007812 seconds
[Rasterizer Renderer] [info] finished render data load
vertex_processed:17568 frag_num:9908 dropped:923 rasterized: 5856 [Rasterizer Renderer] [info] rendering (single thread) takes 0.003906 seconds
[Rasterizer Renderer] [info] finished render data load
vertex_processed:17568 rasterized: 5856 frag_num:3044 dropped:1263 [Rasterizer Renderer] [info] rendering (single thread) takes 0.007812 seconds
[Rasterizer Renderer] [info] finished render data load
Solution
Changed the declaration of Context::rasterizer_finish in the header file to a mutex variable and its definition in rasterizer_renderer.cpp. The issue was resolved.

vertex_processed:17568 rasterized: 5856frag_num:7929 dropped:2755 [Rasterizer Renderer] [info] rendering (single thread) takes 0.005859 seconds
[Rasterizer Renderer] [info] finished render data load
vertex_processed:17568 rasterized: 5856frag_num:7929 dropped:2755 [Rasterizer Renderer] [info] rendering (single thread) takes 0.007812 seconds
[Rasterizer Renderer] [info] finished render data load
vertex_processed:17568 rasterized: 5856frag_num:7929 dropped:2755 [Rasterizer Renderer] [info] rendering (single thread) takes 0.005859 seconds
[Rasterizer Renderer] [info] finished render data load
vertex_processed:17568 rasterized: 5856frag_num:7929 dropped:2755 [Rasterizer Renderer] [info] rendering (single thread) takes 0.005859 seconds
[Rasterizer Renderer] [info] finished render data load
I did not modify other threads or queue‑related parts of the original project. After reviewing the code repeatedly, I don’t see any issue with the original ordering and don’t understand how, after compiler optimizations, the fragment worker thread could read rasterizer_finish=true before the modification. The problem was solved by changing the source code.