Pintos 的调试是在 qemu 虚拟机和 bochs 虚拟机中进行。在开启调试模式之后,你可以在某些内存地址设置断点,这些虚拟机内的虚拟 CPU 执行到位于这些内存地址的指令时就会停下来,然后你就可以打印内存中的值或者寄存器中的值来进行调试。Pintos 提供了一系列 gdb 的宏,在载入这些宏之后的调试体验和普通的 C/C++ 调试差不多。
好完备的 proj 啊,感觉要花好久做
我感觉四个人平均还要 2k 行代码已经很能说明问题了 ![]() 毕竟这是实验代码,不是业务搬砖。图形学这边 Dandelion 框架本体有 6k+ 行代码,但我只能设计出不到 1k 行的实验空间来。光是留给同学的空间就多达 8k+ 行,我听着都很震撼。
毕竟这是实验代码,不是业务搬砖。图形学这边 Dandelion 框架本体有 6k+ 行代码,但我只能设计出不到 1k 行的实验空间来。光是留给同学的空间就多达 8k+ 行,我听着都很震撼。
没有那么多,四人一共 2k 行差不多。主要工作集中在 design 上面,实现并不难
Project 1 userprog

Project 2 threads

Project 3 File systems

从 cs162 的文档拿了几张图,上图直观地展示了 staff 的解决方案的代码变动,从中可以看出所有的 projects 一共需要写两千多行代码
「いいね!」 4
你已经 12h 没学习了,快开始吧,我就指望看着你的笔记学呢
「いいね!」 1
糟糕,我被门友包围了
「いいね!」 1
![]() 闹钟响了,昨天在准备面试来着
闹钟响了,昨天在准备面试来着
![]() 你不是好多 offer 了吗
你不是好多 offer 了吗
好厉害![]() 今天我体验了一下天王星的面试
今天我体验了一下天王星的面试![]()
我的评价是:我必挂
上海还是深圳啊,他们不太一样的,分的挺开
深圳,
挂了肯定![]()
深圳你找我内推呀![]() 万一就过了呢
万一就过了呢
我啥也不会![]()
![]()
![]() 推我不会对你有坏影响吧
推我不会对你有坏影响吧![]()
现在是成都那边的人面我,但是给我说成都和深圳是一个组
是一个组,成都和深圳一起的,上海单独的。
不会有坏影响啊,我都离职了
原来如此![]()
Lecture2. 四个 OS 的基本概念
- Thread
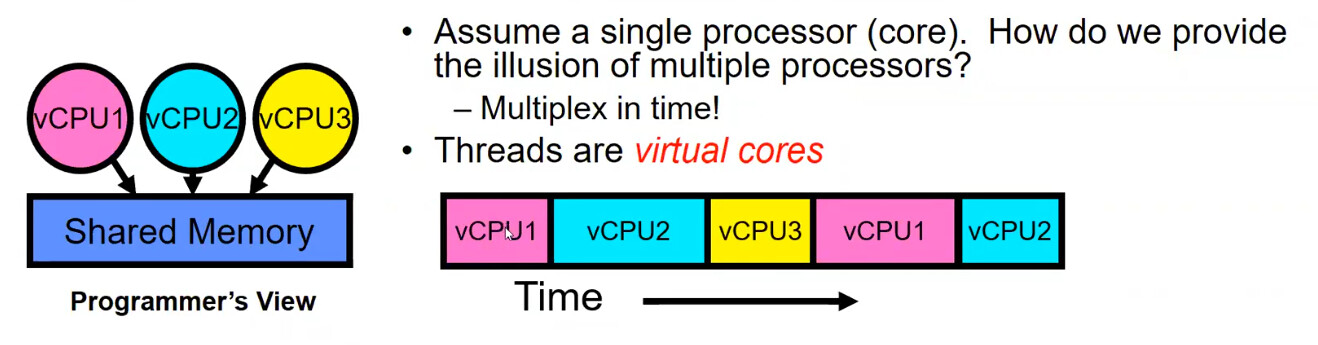
很有趣的说法,线程就是虚拟核心(也就是处理器)
一个处理器(核心)上如何运行多个 Thread,给出一种好像有很多个线程的假象呢?可以像右侧图中这样随时间不断地切换当前正在运行的 Thread(vCPU)。
同时这里还给出了 Thread Control Block—TCB 的定义,我们在某个处理器中切换 Thread 的时候,为了下一次能够继续正常运行切换前的 Thread,我们需要把它内部的状态(例如寄存器信息,PC,Flags(可能是指控制器的状态?)等等)存储到内存中,这里这些状态信息就是 TCB。
同时这里涉及到一个问题:
每个 Core 往往都拥有自己独立的缓存,根据 NUMA 架构,每个 CPU Node 中所有的 Cores 会 Share L3 Cache,在此之上,每个 Core 都各自含有一层 L2 Cache 和 L1 Cache(L1 分为指令缓存和数据缓存两部分)。
因此如果我们频繁的在同一个 Core 上切换其运行的 Thread,如果有某个 Thread 极其吃缓存,就会导致每次切换带来巨大的 Cache Miss 开销,比起单核单线程运行时的性能将会大大降低。
除此之外,单次线程切换的开销大概是数微妙,如果切换的过于频繁,会导致严重的性能下降。
触发切换的可能情景:计时器(类似于 Round Robin 每次分配运行时间片?),一些可以异步的操作(例如 IO 操作,这时候会安排别的 Thread 运行),或者自愿放弃持有 Core 的资源。
我们该如何确定 Thread 们的运行是正确的呢?
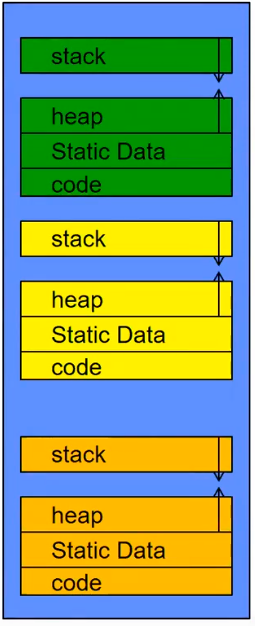
这张图里有三个 Thread 的内存结构,我们发现除此之外,Thread 需要保存的信息仍然很多,因此 TCB 中的信息往往是压缩过的(例如流水线中的信息将会被全部清空)。
Kubi 说这里暂且认为 TCB 中的信息保存在内存中,尤其指明保存在内核占用的内存中。
「いいね!」 2
- Address Space
2.1 基本的地址空间细节
Address Space 是可访问的地址的集合。
它由这些部分构成:
栈区:用来给 Thread 存储临时变量,函数递归栈帧等
堆区:用来动态分配内存
数据区:存储静态变量,全局变量等
代码区:存储可执行代码
考虑在同一个 Core 中,除了堆栈指针,Program Counter,寄存器等,剩下的资源均是他们所共享的。
因此会带来一定的不安全性,每个 Thread 都可以访问在同一个 Core 上运行的其他 Thread 的内存。
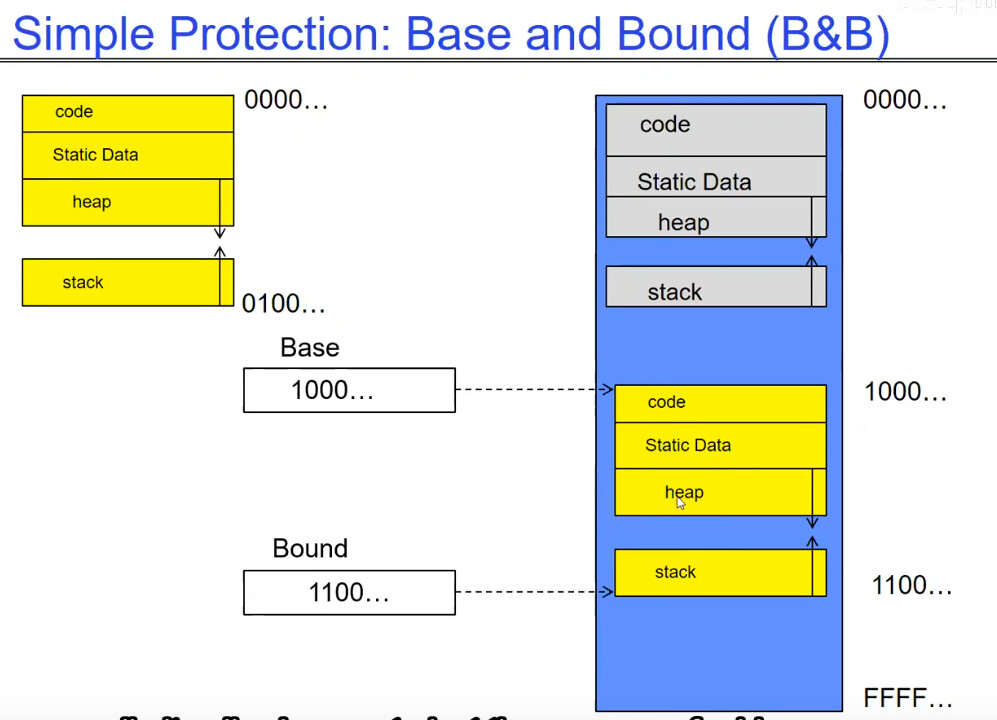
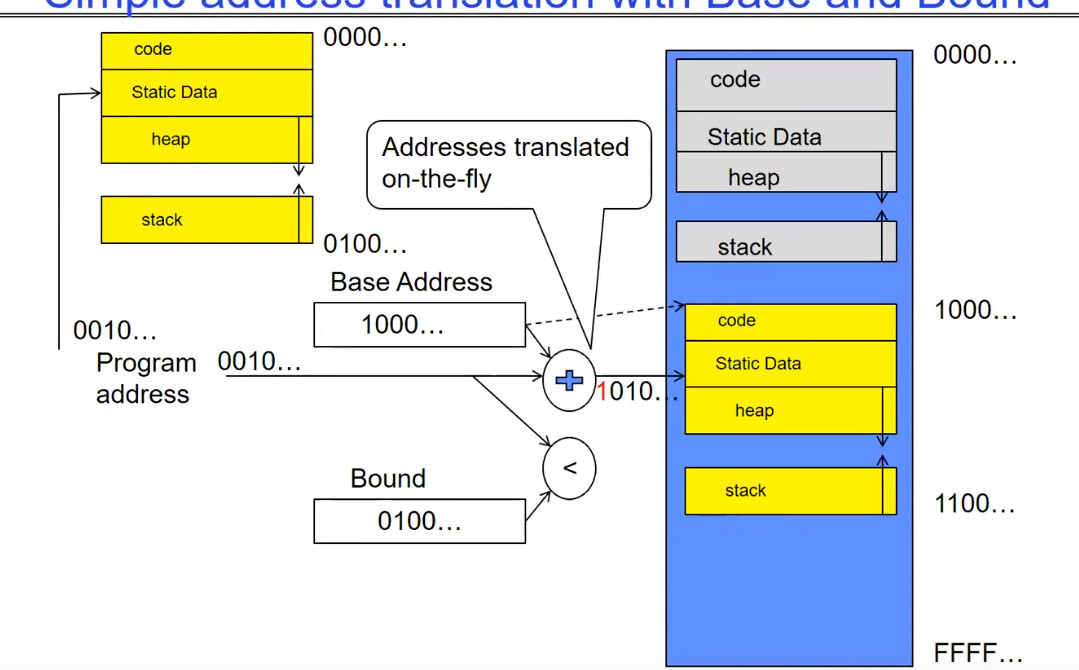
上图带来了一个简单的处理方法:
使用 Base & Bound 寄存器表示一个 Thread 可以访问的内存的范围,限制某个 Thread 只可以访问 [Base, Bound) 范围内的地址空间,这样可以很有效的阻止 Thread 访问其他不由他管辖的内存。
另一个非常简单的 Base & Bound 实现方式如下图:
使用一个加法器,程序需要访问的内存位置 x 实际上需要访问 Base + x 的内存位置,我们只需要判断 Base + x 是否 < Bound 即可。这实际上使得每个程序中都可以认为自己所在的内存地址是从 0000…开始的,方便了程序的编辑。
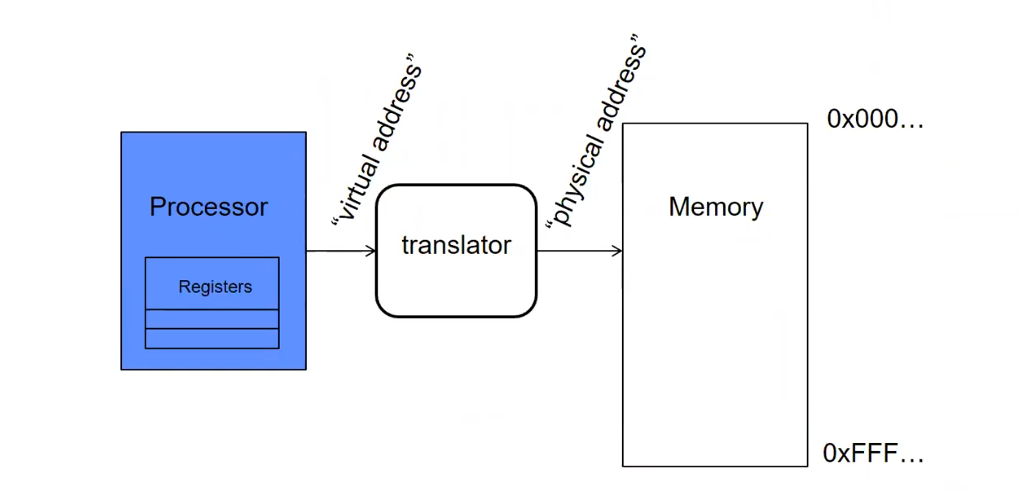
我们刚刚完成了对 x 到其对应物理内存的一个极其简单的翻译,这实际上揭示了一种更加通用的内存地址转换模型。如上图所示,处理器给出虚拟的内存地址,经由翻译器获得其实际的物理地址。
2.2 页
为什么要使用页呢?
考虑一种情况:某个 Thread 占用的内存不够用(例如一直在 Allocate 新的内存,导致原本预定占用的堆区爆满),这时唯一的做法就是将其目前占用的内存全部剪切到另一片更大的内存区域中。如果这种操作频繁发生,不断的在原本被占用的长段内存中“打洞”,在原本未被占用的内存中间“填充”,这将会导致严重的内存碎片化,这个问题的解决方法将在后面的课程中学到。
除此之外,剪切本身也是一件相对困难的事情,但是如果整个内存被分为一页一页的,我们就可以按页地安置每一页内存。
2.3 页表
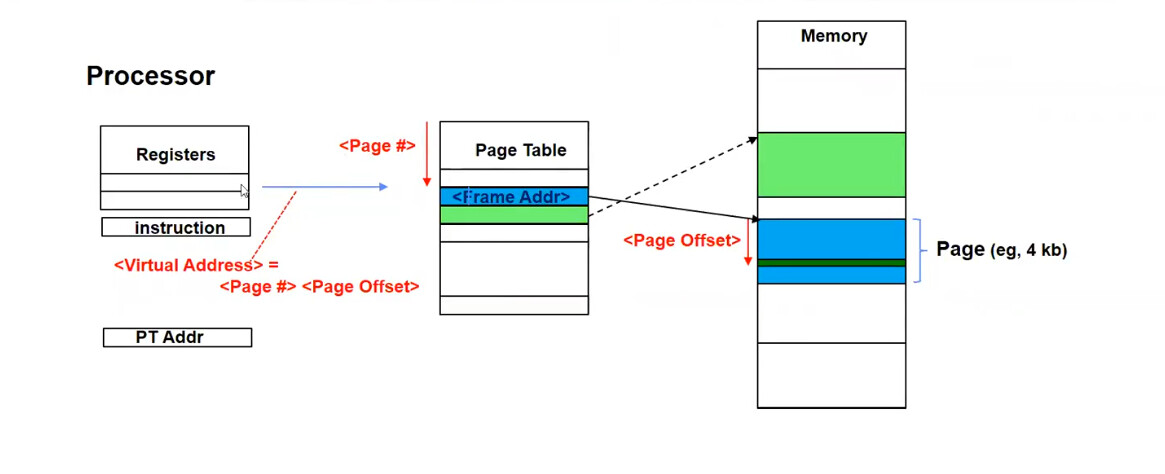
我们该如何按页维护内存并完成虚拟地址到物理地址的翻译呢?
使用页表作为翻译器。
如上图所示,处理器给出的虚拟地址将包括两个关键内容,一个是页号,另一个是业内偏移量,由于所有的页大小均相同,因此我们通过页号在页表内查询到对应物理地址所在的页,再使用页内偏移量即可找到在这一页中要查询的地址所在的位置。
「いいね!」 1
- Process
进程是一个拥有受限制权限的执行环境。(哈哈,终于有一个不是“系统资源调度的基本单位“的说法了)
注意到上文中并未区分 Thread 和 Process,因此这一节会有一小部分颠覆前两节的说法。
进程拥有一定的受限制的地址空间(比如使用 base bound 限制),文件描述符,文件系统上下文,拥有一些共享某些资源的 Threads。
出于对于安全性考虑的刻意的设计,在同一进程中的不同线程的交流很简单,在不同进程中的线程交流很困难。
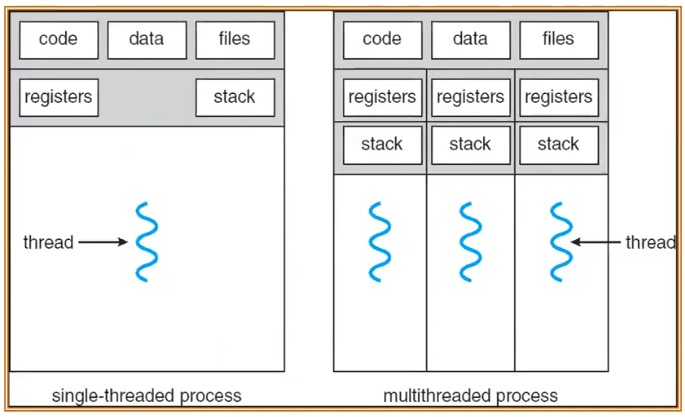
这张图很好的揭示了为什么同一进程中的不同线程交流很简单,因为他们的 Code Data Fils 都是共享的。
因此,出于对安全性和可靠性的考虑,我们要求进程只能修改自己的内存,避免了对其他进程的影响。
「いいね!」 1
- Dual Mode
考虑为什么进程 A 的页表指针不能指向进程 B?
因为这会破坏进程间的数据隔离。
那我们该如何在必要时使用这种操作呢?这就要求硬件至少提供两种模式:内核模式和用户模式。
下一个问题是该如何控制两种模式间的过渡和切换?
简单来说,如上图:调用系统调用 syscall,系统调用会支配硬件完成某些工作,然后结束 syscall 返回用户模式。
注意到至少提供两种模式,后续在 Docker 中我们将了解到更多的权限介于二者之间的模式。
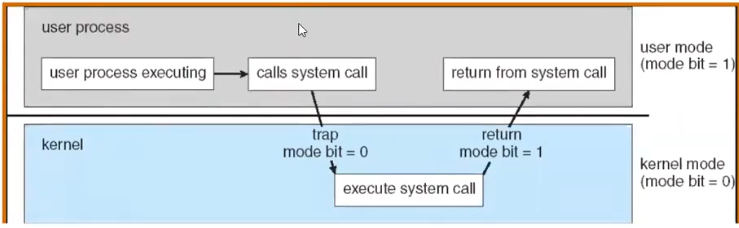
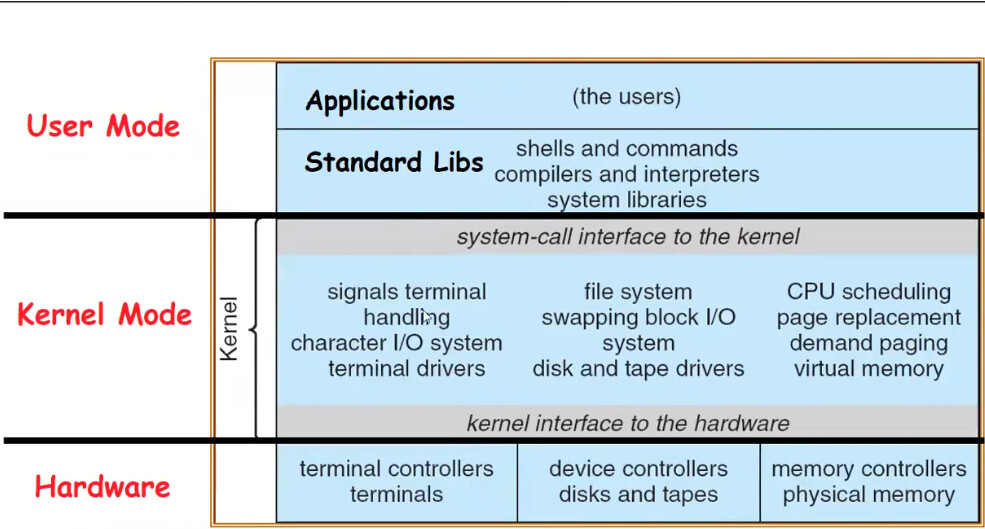
「いいね!」 1
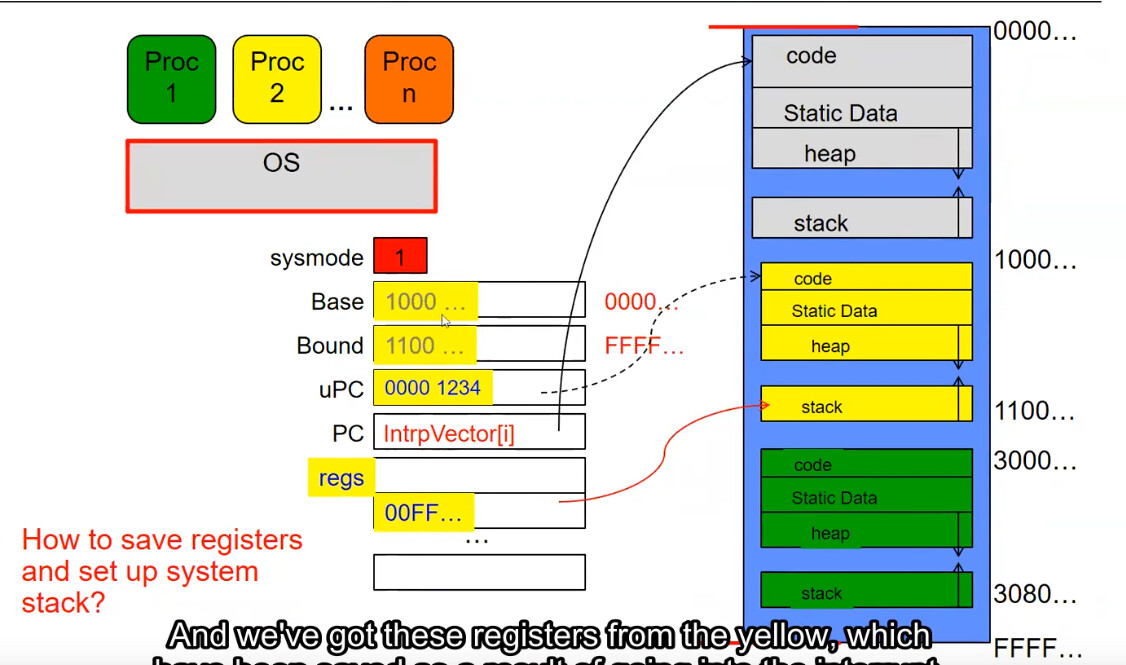
- 一个例子
最开始处于内核模式,可以注意到其 Base 和 Bound 均失效(意味着可以访问 [0000…, FFFF…] 的所有地址空间),uPC 指向黄色进程的可执行代码,意味着目前想要加载进入黄色进程。
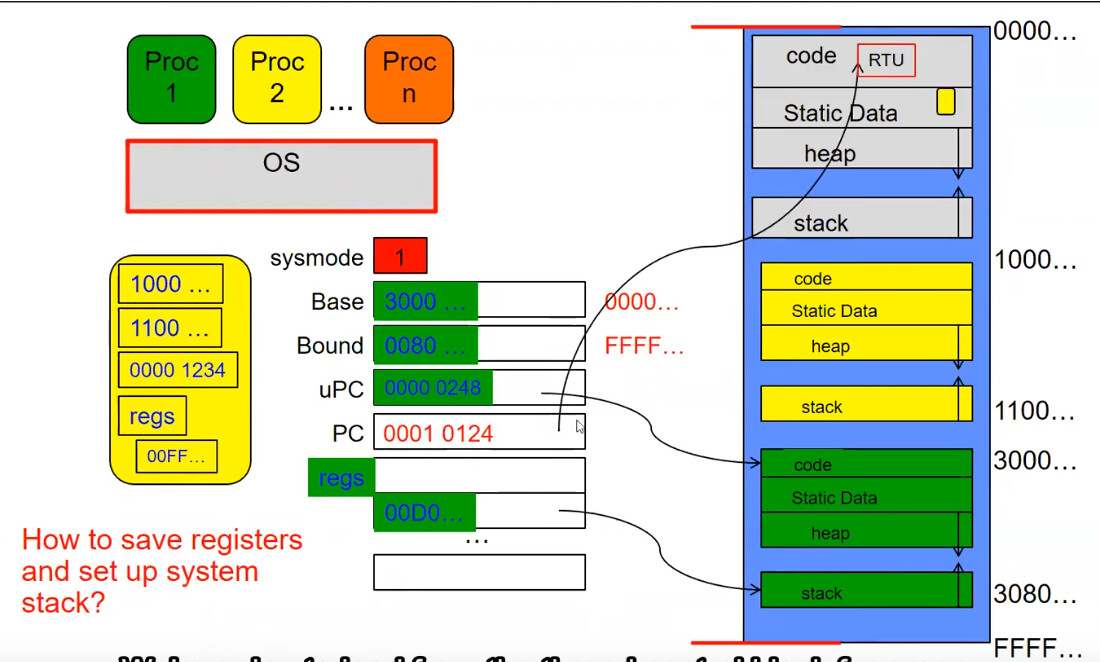
我们将 PC 换为之前的 uPC,sysmode 改为 0 之后,Base 和 Bound 就激活了且等于黄色的地址区域边界,这意味着我们进入了黄色进程,同时进入了用户模式。
假设一段时间后发生了计时器中断,下一条执行的指令将会是计时器中断处理程序(存在于内核代码区),中断发生后我们又一次进入了内核态。
由于要发生进程切换,因此计时器中断处理程序将会保存黄色进程 PCB 并放入内核区(灰色)的 Static Data 中的黄色小方块。
同时我们加载切换到绿色所需的寄存器信息。
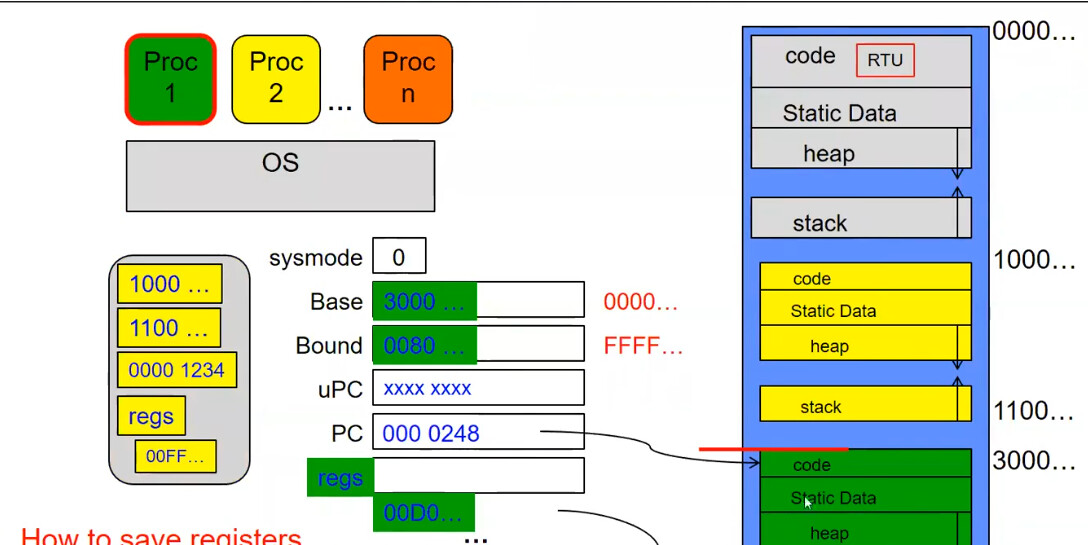
更改 sysmode 后成功以用户模式运行绿色进程。
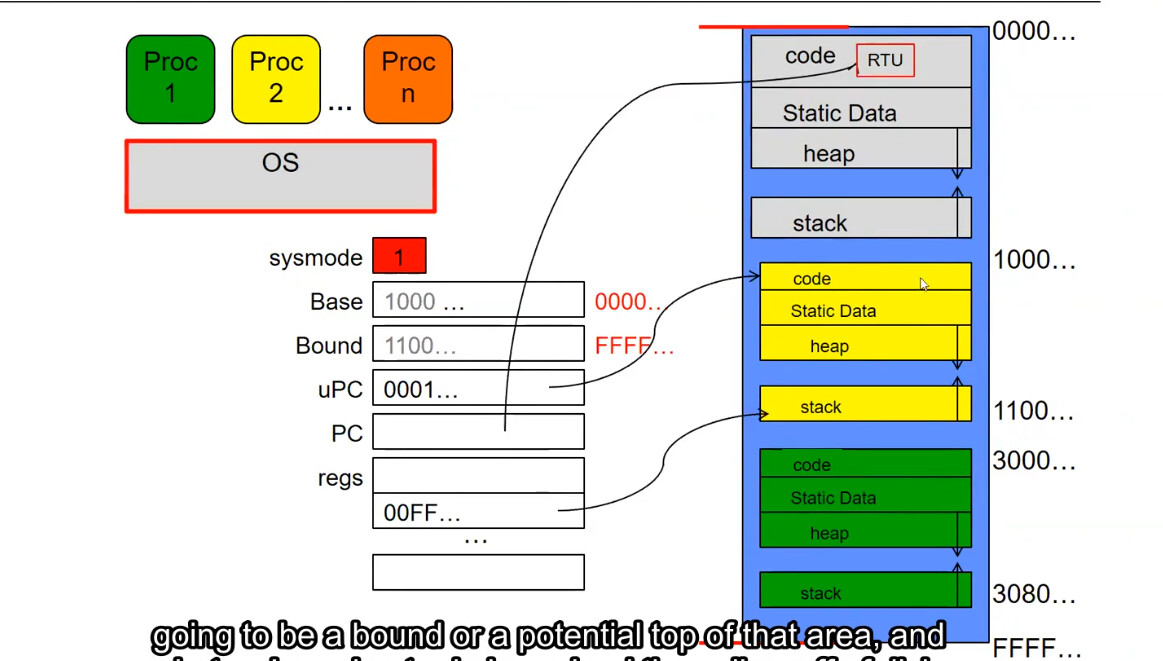
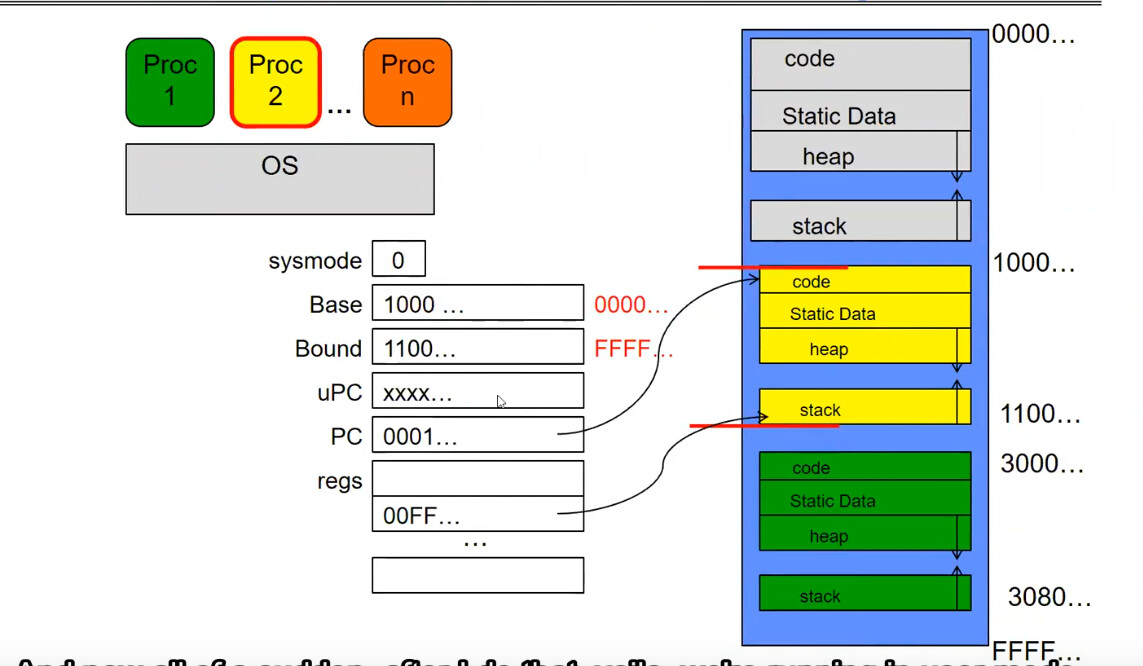
「いいね!」 1